
Variational Auto Encoder
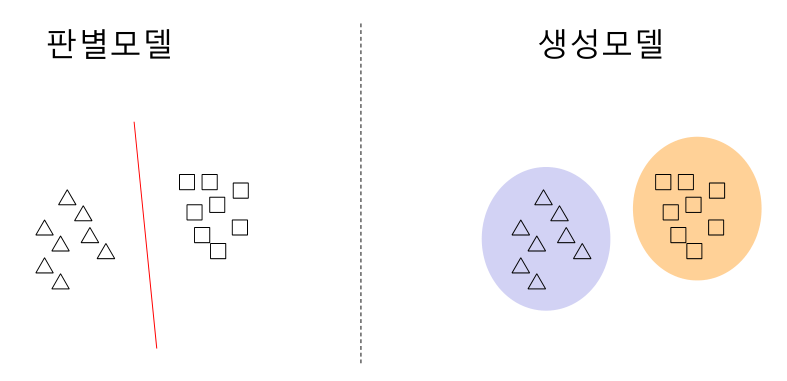
판별 모델 과 생성 모델의 차이
일반적인 기게학습은 판별모델 (discriminative model)이다.
일반적으로 dnn 의 classification , detection , segmentation 도 여기에 해당됨.
생성 모델은 판별과는 다르게 데이터셋의 범위를 고려함.
Main Concept
VAE 는 데이터가 생성되는 과정 , 즉 데이터의 확률 분포를 학습하기 위한 두개의 뉴럴네트워크로 구성되어있다. VAE 는 잠재변수(Latent vairable) z 를 가정하며 encoder 라 불리는 rnn 은 관측된 데이터 x 를 받아 잠재변수 z 를 생성하고 decoder 라 불리는 rnn 은 관측된 데이터 x 를 받아서 잠재변수 z 를 만든다.
deocder 는 encoder 가 만든 z 를 활용하여 x 를 복원하는 역활을 수행한다.

What to do ?
이미지와 같은 고차원 데이터 X 의 저차원 표현 z(Latent space) 를 구한다면 z 를 조정하여 training set 에 주어지지 않은 새로운 이미지 생성이 가능하다.
z 에는 카메라 각도 , 조명위치 , 표정 등이 포함될수 있음.

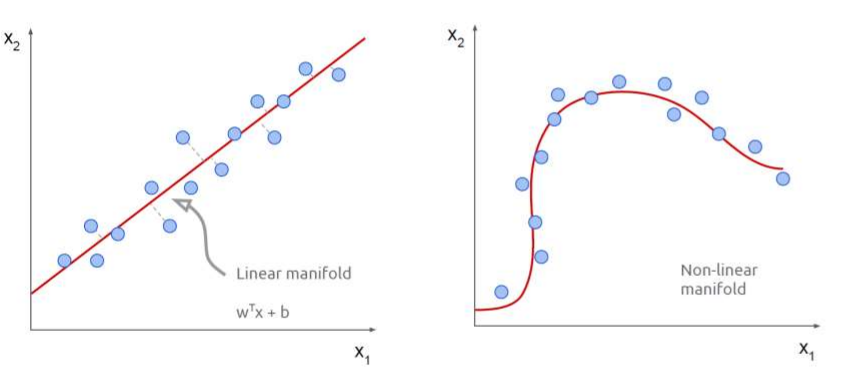
Manifold hypothesis
결국 고차원 데이터를 저차원 데이터로 표현할수 있는가 에 대한 문제가 발생하고 이는 Manifold hypothesis 에 해당함.
latent space
잠재공간을 설명하자면 차원 축소에 대한 이야기를 먼저 시작해야한다.
만약 우리가 훈련에 필요한 고차원의 입력값을 보유하고 있다고 가정하면 모든 feature 가 필요하지 않을수도 있고 갖고 있는 feature 중 몇개는 다른 특징 조합으로 표현할수 있어 불필요할수 있다. 따라서 관찰대상들을 잘 설명할수 있는 잠재공간(Latent space) 는 실제 관찰 공간 (observation space) 보다 작을수 있다.
이렇게 관찰공간 위의 샘플 기반으로 잠재 공간을 파악하는것이 차원 축소(dimensionality reduction) 라 한다.
즉 차원 축소는 데이터의 압축 , 잡음 제거 효과등이 있지만 가장 중요한 의미로는 관측 데이터를 잘 설명할수 있는 잠재 공간(Latent space) 를 찾는것이다.
결국 이 잠재공간에 존재하는 잠재변수의 분포를 학습 하는것이 목적
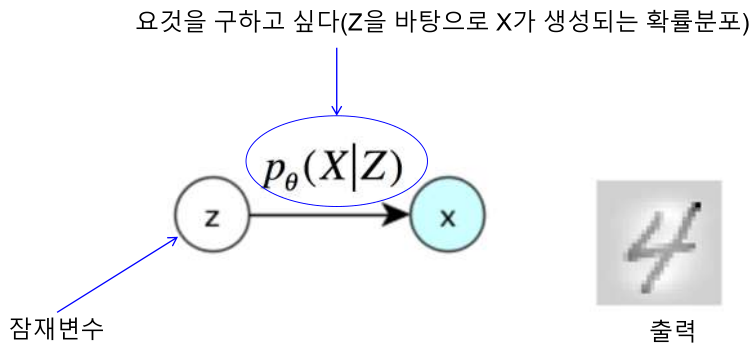
Encoder
Encoder 를 먼저 만들면 랜덤 백터 z 를 입력 받아 가짜 이미지 x 를 생성한다. 이때 z 는 단순히 Uniform distribution 또는 Normal distirbution 에서 무작위 추출된 값임.
즉 입력 -> 잠재변수 분포를 생성 \(Q_{\theta}(Z|X^{(i)})\)
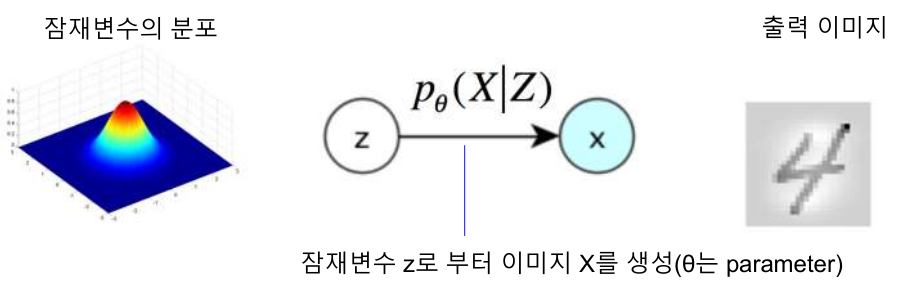
Decoder
Decoder는 잠재변수로 부터 샘플링을 하여 입력에 가까운 출력을 생성 하는 역활 잠재변수 샘플링 -> 출력 \(P_{\theta}(X^{(i)}|Z)\)
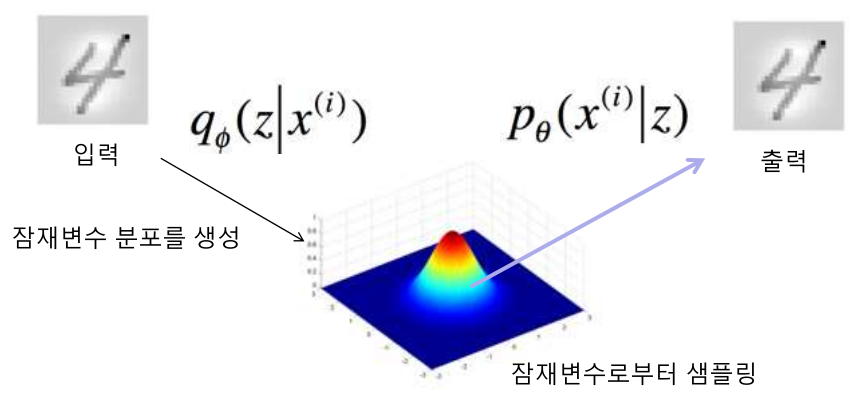
VAE 구조
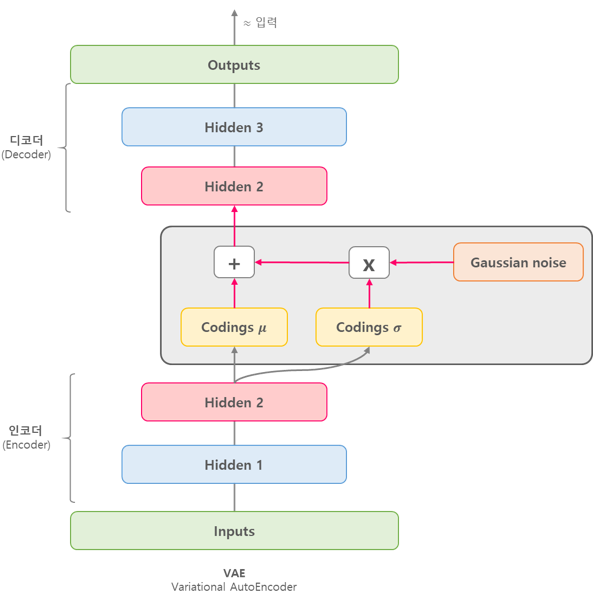
그림출처 : https://excelsior-cjh.tistory.com/187