APEX 를 활용한 pytorch distributed training 방법
Pytorch Distributed with APEX
Apex 는 NVIDAI 에서 제공하는 Pytorch 용 extension 으로서 주된 기능은 다음 4개와 같다.
- Automatic Mixed Precision
- Distributed Training
- Fused Optimizers
- Fused Layer Norm
이번 블로그에는 이중 Distributed Training 에 대한 sample code 와 내용을 담아보려 한다.
Distributed Training
pytorch 에 는 기본적으로 multi gpu 사용을 위한 DataDistribution 기능이 존재한다.
다만 해당 기능을 사용할경우 GPU 0번에 메모리 할당이 주로 되어 진정한 gpu memory sharing 이 되지 않는다.
apex 는 기존 pytorch DistributedDataParallel의 wrapper 로서 multiprocess distributed data parallel training 을 쉽게 구현할수 있게한다.
머신에 상관없이 각 GPU 는 개별적 H/W 구성 요소로 잡혀 Distributed 수행이 된다.
자세한 설명은 생략하고 코드로 대체해보자.
해당 예제는 Deeplabv3 plus (bcakbone : xception) 기반으로 ADE20k dataset 을 학습 하는 예제임
run
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main_with_apex.py
# torch.distributed.launch 명령어를 기입함으로서 distributed 로 실행하겠다고 명함
# --nproc_per_node=4 는 4개의 GPU 를 사용하겠다 정의
# CUDA_VISIBLE_DEVICES 는 해도되고 안해도 되고.
import argparse
import os
import torch
import torch.distributed
import torch.cuda
import torch.utils.data
import torch.backends.cudnn
from torchvision import transforms
from model.deeplab import *
from SegLoss.SegmentationLosses import *
import json
from collections import namedtuple
from util import *
import numpy as np
from tqdm import tqdm
from apex import amp
from apex.parallel import DistributedDataParallel
def train(epoch, data_loader, model, optimizer):
model.train()
loss_fn = torch.nn.CrossEntropyLoss().cuda()
train_iter = len(data_loader)
train_loss = 0.0
for i, data in enumerate(data_loader):
image, gt = data[0], data[1]
image, gt = image.cuda(non_blocking=True), gt.cuda(non_blocking=True)
optimizer.zero_grad()
output = model(image)
loss = loss_fn(output, gt)
if args.distributed:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
train_loss += loss.item()
optimizer.step()
if args.local_rank == 0:
print(f'Epoch : {epoch} , Train_loss : {train_loss / train_iter}')
def valid(epoch, data_loader, model):
model.eval()
test_iter = len(data_loader)
sum_of_iou = 0
with torch.no_grad():
for i, data in enumerate(data_loader):
images, gts = data[0], data[1]
images, gts = images.cuda(non_blocking=True), gts.cuda(non_blocking=True)
outputs = model(images)
outputs = F.softmax(outputs, dim=1)
_, predicted = torch.max(outputs, dim=1)
sum_of_iou += iou_pytorch(predicted, gts)
if args.local_rank == 0:
print(f'Epoch : {epoch} , iou : {sum_of_iou / test_iter}')
return sum_of_iou
def main(args):
torch.backends.cudnn.benchmark = True
model = DeepLab(num_classes=args.num_class)
# apex 에 있는 batch synchronization 기능
if args.sync_bn:
import apex
model = apex.parallel.convert_syncbn_model(model)
model = model.cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
if args.distributed:
# mixed precision 을 사용하겠다고 선언
model, optimizer = amp.initialize(model, optimizer)
# apex.DistributedDataParallel 모델정의
model = DistributedDataParallel(model)
train_dataset = ADE20KSegmentation(args.root_dataset)
valid_dataset = ADE20KSegmentation(args.root_dataset, mode='test')
train_sampler, valid_sampler = None, None
if args.distributed:
# multiprocess 이기 때문에 각 GPU 마다 dataset 이 나뉘어 들어가 져야 하기 때문에 적용
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
valid_sampler = torch.utils.data.distributed.DistributedSampler(valid_dataset)
train_dataset_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.train_batch_size, shuffle=(train_sampler is None),
num_workers=args.num_worker,
pin_memory=True, collate_fn=train_dataset.collate_fn)
valid_dataset_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=args.valid_batch_size, shuffle=(valid_sampler is None), num_workers=args.num_worker,
pin_memory=True, collate_fn=valid_dataset.collate_fn)
save_path = './weight'
for i in range(args.epochs):
if args.distributed:
train_sampler.set_epoch(i)
train(i, train_dataset_loader, model, optimizer)
iou = valid(i, valid_dataset_loader, model)
if i % 5 == 0 and args.local_rank == 0:
model_save_path = save_path + f'/{i}'
os.mkdir(model_save_path)
checkpoint = {'model': model.state_dict(), 'optimizer': optimizer.state_dict(), 'amp': amp.state_dict()}
torch.save(checkpoint, model_save_path + f'/weight.pth')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--config', default='./config/ade20k-xception.json')
parser.add_argument('--local_rank', default=0, type=int)
args = parser.parse_args()
distributed = False
local_rank = 0
if 'WORLD_SIZE' in os.environ:
# print(os.environ['WORLD_SIZE'])
distributed = int(os.environ['WORLD_SIZE']) > 1
if distributed:
# GPU 개별적 distributed를 하기 위한 backend 로 nccl 을 사용하고 로컬에 GPU 를 사용하기 때문에 init_method='env://'
torch.distributed.init_process_group(backend='nccl', init_method='env://')
# 앞서 --nproc_per_node=4 를 기입함으로서 해당 코드가 multiprocess 로 실행 되면서 local_rank 값이 각 GPU 마다 indexing 되어져서 들어옴
local_rank = args.local_rank
with open(args.config, 'r') as f:
args = json.load(f, object_hook=lambda d: namedtuple('config', d.keys())(*d.values()))
args = args._replace(distributed=distributed)
args = args._replace(local_rank=local_rank)
# multiprocess call 이 되기 때문에 각 device 별로 set_device 를 수행
torch.cuda.set_device(args.local_rank)
main(args)
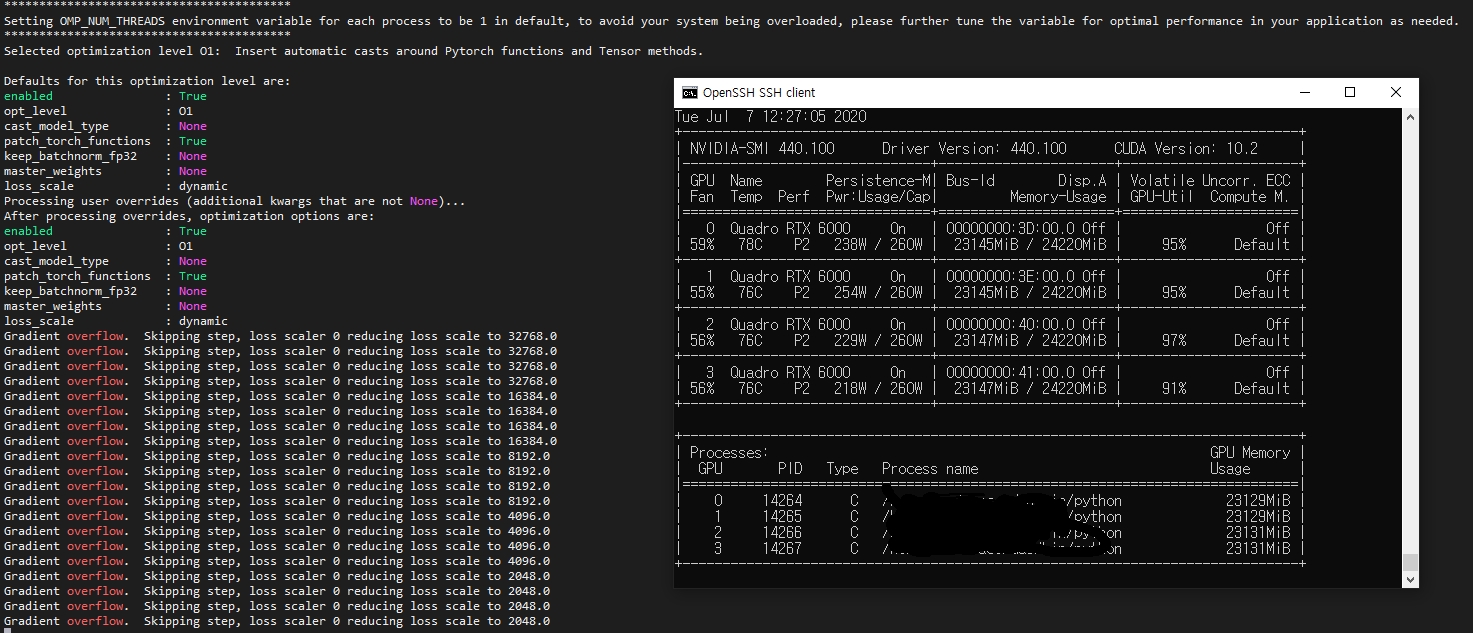
실행결과는 다음과 같이…